Coursera Deep Learning Specialization Notes
2023-03-26Pre-Requisites
- Docker and docker-compose are installed and running on your system.
docker-compose file
Below is a docker-compose file to set up a Spark cluster with 1 master and 2 worker nodes.
version: '3.7'
services:
spark-master:
image: bitnami/spark:latest
container_name: spark-master
command: bin/spark-class org.apache.spark.deploy.master.Master
ports:
- "9090:8080"
- "7077:7077"
spark-worker-1:
image: bitnami/spark:latest
container_name: spark-worker-1
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
depends_on:
- "spark-master"
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_MASTER_URL: spark://spark-master:7077
spark-worker-2:
image: bitnami/spark:latest
container_name: spark-worker-2
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
depends_on:
- "spark-master"
environment:
SPARK_MODE: worker
SPARK_WORKER_CORES: 2
SPARK_WORKER_MEMORY: 2g
SPARK_MASTER_URL: spark://spark-master:7077
This setup uses the bitnami/spark image. You can add more workers and also change the SPARK_WORKER_CORES and SPARK_WORKER_MEMORY in the environment based on your system’s specifications.
After creating the docker-compose.yml file, you just need to go to the directory of the compose file and type:
docker-compose up -d
This will start your Apache Spark container. Run the following command to ensure all containers are running:
docker ps

Run spark-submit
Now that the Spark container is up and running, we need to test if it is working. Create a simple PySpark script using spark-submit command and save it as pi.py.
# pi.py
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_: int) -> float:
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()
This is a simple PySpark to calculate PI value.
After setting up the program, we need to copy it to the spark container. To do this, we can use docker cp command.
docker cp -L pi.py spark-master:/opt/bitnami/spark/pi.py
Now we need to get the address where our spark master is running. To do that, we need to use docker logs command.
docker logs spark-master
After running this command, you need to find the address which will look something like this:

Here, the Spark Master is running at spark://172.20.0.2:7077.
Now we need to execute the pyspark file using the following command
docker exec spark-master spark-submit --master spark://172.20.0.2:7077 pi.py
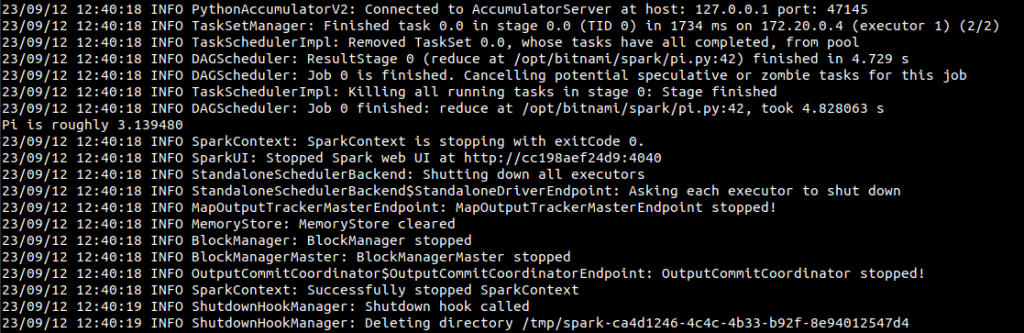
If the program is executed properly, it will display the PI value as below:
To stop the containers, type the following command.
docker-compose down

{kind=link}